这是分布式缓存系统,也就是每个机器都不会存重复的键值。原理是一致性Hash,每个机器通过同一个端口实现通信。按照机器id来安排键值和取值。
Ref
https://blog.51cto.com/lookingdream/1941822
Monday, October 21, 2019
Monday, October 7, 2019
AWS CloudFormation简介
AWS CloudFormation是AWS资源的配置文件以及AWS资源间的关系。就是将手动的配置代码化。
主要有两种模板:JSON和YAML
Stack:
CloudFormation模板中定义的所有AWS资源及其配置,只有deploy以后程序就可以运行。Events中可以看到stack为什么deploy失败,若失败后会自动回滚。deploy需时较长,因为要创建那些AWS资源如lambda,sqs等。
Ref
模板参考
主要有两种模板:JSON和YAML
Syntax:
"Fn::And": [{condition}, {...}] #Json
Fn::And: [Condition] #yaml full syntax
!And [condition] #short form
Stack:
CloudFormation模板中定义的所有AWS资源及其配置,只有deploy以后程序就可以运行。Events中可以看到stack为什么deploy失败,若失败后会自动回滚。deploy需时较长,因为要创建那些AWS资源如lambda,sqs等。
Ref
模板参考
Tuesday, July 23, 2019
Monday, July 15, 2019
TestNG
TestNG是一个设计用来简化广泛的测试需求的测试框架,从单元测试(隔离测试一个类)到集成测试(测试由有多个类多个包甚至多个外部框架组成的整个系统,例如运用服务器)。
@BeforeSuite: 被注释的方法将在所有测试运行前运行
@AfterSuite: 被注释的方法将在所有测试运行后运行
@BeforeTest: 被注释的方法将在测试运行前运行
@AfterTest: 被注释的方法将在测试运行后运行
@BeforeGroups: 被配置的方法将在列表中的gourp前运行。这个方法保证在第一个属于这些组的测试方法调用前立即执行。
@AfterGroups: 被配置的方法将在列表中的gourp后运行。这个方法保证在最后一个属于这些组的测试方法调用后立即执行。
@BeforeClass: 被注释的方法将在当前类的第一个测试方法调用前运行。
@AfterClass: 被注释的方法将在当前类的所有测试方法调用后运行。
@BeforeMethod: 被注释的方法将在每一个测试方法调用前运行。
@AfterMethod: 被注释的方法将在每一个测试方法调用后运行。
Ref:
https://blog.csdn.net/chaoren2011/article/details/38932967
@BeforeSuite: 被注释的方法将在所有测试运行前运行
@AfterSuite: 被注释的方法将在所有测试运行后运行
@BeforeTest: 被注释的方法将在测试运行前运行
@AfterTest: 被注释的方法将在测试运行后运行
@BeforeGroups: 被配置的方法将在列表中的gourp前运行。这个方法保证在第一个属于这些组的测试方法调用前立即执行。
@AfterGroups: 被配置的方法将在列表中的gourp后运行。这个方法保证在最后一个属于这些组的测试方法调用后立即执行。
@BeforeClass: 被注释的方法将在当前类的第一个测试方法调用前运行。
@AfterClass: 被注释的方法将在当前类的所有测试方法调用后运行。
@BeforeMethod: 被注释的方法将在每一个测试方法调用前运行。
@AfterMethod: 被注释的方法将在每一个测试方法调用后运行。
Ref:
https://blog.csdn.net/chaoren2011/article/details/38932967
Monday, July 8, 2019
AWS Athena
用SQL直接在S3中轻松分析数据。类似于Redshift,文件存在硬盘,然后写SQL去query。当然Athena也并不需要source一定要在S3,可以直接写SQL创表。
功能
Athena是无服务器的,因此您无需设置或管理任何基础设施,且只需为您运行的查询付费
Athena分析在S3中存储的非结构化、半结构化和结构化数据包括CSV、JSON 或列式数据格式
Athena 可与 Amazon QuickSight 集成,轻松实现数据可视化。
Athena采用称作基于读取的架构的方法,这意味着,架构将在您执行查询时投影到您的数据上。
这样就无需加载或转换数据。
Athena 不会修改您在 Amazon S3 中的数据。
底层API
用Apache Hive实现
功能
Athena是无服务器的,因此您无需设置或管理任何基础设施,且只需为您运行的查询付费
Athena分析在S3中存储的非结构化、半结构化和结构化数据包括CSV、JSON 或列式数据格式
Athena 可与 Amazon QuickSight 集成,轻松实现数据可视化。
Athena采用称作基于读取的架构的方法,这意味着,架构将在您执行查询时投影到您的数据上。
这样就无需加载或转换数据。
Athena 不会修改您在 Amazon S3 中的数据。
底层API
用Apache Hive实现
jobId改成int会出错
Ref
官方文档
CREATE EXTERNAL TABLE IF NOT EXISTS default.docu_jobs (
`jobId` string,
`title` string,
`url` string,
`location` string,
`runDate` string,
`createdTime` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
"separatorChar" = ",",
"quoteChar" = "\"",
"skip.header.line.count" = "1"
) LOCATION 's3://jctech-data/docu/'
TBLPROPERTIES ('has_encrypted_data'='false');
Ref
官方文档
https://aws.amazon.com/blogs/aws/amazon-athena-interactive-sql-queries-for-data-in-amazon-s3/
Sunday, July 7, 2019
AWS SES
电子邮件平台
功能
* Amazon SES 控制台 — 此方法是设置系统和发送一些测试电子邮件的最快方法,但在您准备好开始电子邮件活动后,将主要使用控制台来监控发送活动。例如,您可以快速查看您已发送的电子邮件数和您收到的退回邮件和投诉邮件数。类似于GoDaddy的console
* SMTP 接口 — 可通过 SMTP 接口以两种方式访问 Amazon SES。第一种方式是将任何支持 SMTP 的软件配置为通过 Amazon SES 发送电子邮件,此方式不需要编码。例如,您可以将现有电子邮件客户端或软件程序配置为连接到 Amazon SES SMTP 终端节点,而不是当前出站电子邮件服务器。第二种方式是使用与 SMTP 兼容的编程语言 (例如 Java) 并使用该语言的内置 SMTP 函数和数据类型访问 Amazon SES SMTP 接口。
* Amazon SES API — 您可以直接通过 HTTPS 调用 Amazon SES 查询 API
Ref
官方文档
功能
* Amazon SES 控制台 — 此方法是设置系统和发送一些测试电子邮件的最快方法,但在您准备好开始电子邮件活动后,将主要使用控制台来监控发送活动。例如,您可以快速查看您已发送的电子邮件数和您收到的退回邮件和投诉邮件数。类似于GoDaddy的console
* SMTP 接口 — 可通过 SMTP 接口以两种方式访问 Amazon SES。第一种方式是将任何支持 SMTP 的软件配置为通过 Amazon SES 发送电子邮件,此方式不需要编码。例如,您可以将现有电子邮件客户端或软件程序配置为连接到 Amazon SES SMTP 终端节点,而不是当前出站电子邮件服务器。第二种方式是使用与 SMTP 兼容的编程语言 (例如 Java) 并使用该语言的内置 SMTP 函数和数据类型访问 Amazon SES SMTP 接口。
* Amazon SES API — 您可以直接通过 HTTPS 调用 Amazon SES 查询 API
Ref
官方文档
AWS CloudTrail
AWS账户进行监管、API调用活动
功能
利用事件历史记录,您可以查看、搜索和下载 AWS 账户中过去 90 天的活动。此外,您还可以创建一个 CloudTrail 跟踪来存档、分析和响应您的 AWS 资源的变化
有两类事件可以记录在 CloudTrail 中:管理事件和数据事件。默认情况下,跟踪记录管理事件,但不记录数据事件。
* 管理事件提供对在您 AWS 账户内的资源上执行的管理操作的见解。这些也称为控制层面操作。
* 数据事件提供对在资源上或资源内执行的资源操作的见解。这些也称为数据层面操作。数据事件通常是高容量活动。示例数据事件包括:Amazon S3 对象级别 API 活动(例如,GetObject)
CloudTrail 事件历史记录提供过去 90 天的 CloudTrail 事件的可查看、可搜索和可下载记录
与 CloudWatch Logs 集成使 CloudTrail 能够将您的 AWS 账户中包含 API 活动的事件发送到
CloudWatch Logs 日志组。
功能
利用事件历史记录,您可以查看、搜索和下载 AWS 账户中过去 90 天的活动。此外,您还可以创建一个 CloudTrail 跟踪来存档、分析和响应您的 AWS 资源的变化
有两类事件可以记录在 CloudTrail 中:管理事件和数据事件。默认情况下,跟踪记录管理事件,但不记录数据事件。
* 管理事件提供对在您 AWS 账户内的资源上执行的管理操作的见解。这些也称为控制层面操作。
* 数据事件提供对在资源上或资源内执行的资源操作的见解。这些也称为数据层面操作。数据事件通常是高容量活动。示例数据事件包括:Amazon S3 对象级别 API 活动(例如,GetObject)
CloudTrail 事件历史记录提供过去 90 天的 CloudTrail 事件的可查看、可搜索和可下载记录
与 CloudWatch Logs 集成使 CloudTrail 能够将您的 AWS 账户中包含 API 活动的事件发送到
CloudWatch Logs 日志组。
AWS CloudWatch
实时监控您的AWS资源以及您在 AWS 中运行的应用程序。我用过的是用CloudWatch来自定义面板来显示dynamoDB和SQS,RDS的指标,以及管理应用程序的日志文件。
应用场景
自定义控制面板,以显示有关自定义应用程序的指标
创建警报,例如,您可以监控您的 Amazon EC2 实例的 CPU 使用率以及磁盘读写情况
最佳实践
与 Amazon CloudWatch 一起使用:
* Amazon SNS用于协调和管理向订阅终端节点或客户交付或发送消息的过程。
可结合使用 Amazon SNS 与 CloudWatch 以便在达到警报阈值时发送消息。
* Amazon EC2 Auto Scaling 根据用户定义的策略、运行状况检查和时间表自动启动或终止
Amazon EC2 实例。可将 CloudWatch 警报与 Amazon EC2 Auto Scaling 一起使用以根据需求扩 展 EC2 实例。
* AWS CloudTrail 可用于监控对您的账户的 Amazon CloudWatch API 的调用(包括由 AWS 管理控制台、
* AWS CLI 和其他服务进行的调用)。开启 CloudTrail 日志记录后,CloudWatch 将日志文件写入到您在配置 CloudTrail 时指定的 Amazon S3 存储桶。
* AWS Identity and Access Management (IAM) 是一项 Web 服务,可帮助您安全地控制用户对 AWS 资源的访问权限。通过 IAM 可以控制哪些人可以使用您的 AWS 资源(身份验证)以及他们可以使用的资源和采用的方式(授权)。
架构
AWS资源周期性地将指标上传到CloudWath
应用场景
自定义控制面板,以显示有关自定义应用程序的指标
创建警报,例如,您可以监控您的 Amazon EC2 实例的 CPU 使用率以及磁盘读写情况
最佳实践
与 Amazon CloudWatch 一起使用:
* Amazon SNS用于协调和管理向订阅终端节点或客户交付或发送消息的过程。
可结合使用 Amazon SNS 与 CloudWatch 以便在达到警报阈值时发送消息。
* Amazon EC2 Auto Scaling 根据用户定义的策略、运行状况检查和时间表自动启动或终止
Amazon EC2 实例。可将 CloudWatch 警报与 Amazon EC2 Auto Scaling 一起使用以根据需求扩 展 EC2 实例。
* AWS CloudTrail 可用于监控对您的账户的 Amazon CloudWatch API 的调用(包括由 AWS 管理控制台、
* AWS CLI 和其他服务进行的调用)。开启 CloudTrail 日志记录后,CloudWatch 将日志文件写入到您在配置 CloudTrail 时指定的 Amazon S3 存储桶。
* AWS Identity and Access Management (IAM) 是一项 Web 服务,可帮助您安全地控制用户对 AWS 资源的访问权限。通过 IAM 可以控制哪些人可以使用您的 AWS 资源(身份验证)以及他们可以使用的资源和采用的方式(授权)。
架构
AWS资源周期性地将指标上传到CloudWath
SQS Metrics
DLQ: ApproximateNumberOfMessagesVisible, 15min, Sum
还可以用来计划使用 cron 或 rate 表达式在某些时间自行触发的自动化操作
最佳实践
计划自动化 EBS 快照
当文件上传至 Amazon S3 存储桶时运行 Amazon ECS 任务
在 AWS 账户之间发送和接收事件
架构
事件 —事件表示 AWS 环境中的更改。AWS 资源可以在其状态更改时生成事件。例如,Amazon EC2 在 EC2 实例的状态从待处理更改为正在运行时生成事件
目标—目标负责处理事件。目标可包括 Amazon EC2 实例、AWS Lambda 函数、Kinesis 流、Amazon ECS 任务、Step Functions 状态机、Amazon SNS 主题、Amazon SQS 队列和内置目标。目标接收 JSON 格式的事件。
规则—规则匹配传入事件并将其路由到目标进行处理。
CloudWatch Events
近乎实时的系统事件流,这些系统事件描述 Amazon Web Services (AWS) 资源的变化。通过使用可快速设置的简单规则,您可以匹配事件并将事件路由到一个或多个目标函数或流。还可以用来计划使用 cron 或 rate 表达式在某些时间自行触发的自动化操作
最佳实践
计划自动化 EBS 快照
当文件上传至 Amazon S3 存储桶时运行 Amazon ECS 任务
在 AWS 账户之间发送和接收事件
架构
事件 —事件表示 AWS 环境中的更改。AWS 资源可以在其状态更改时生成事件。例如,Amazon EC2 在 EC2 实例的状态从待处理更改为正在运行时生成事件
目标—目标负责处理事件。目标可包括 Amazon EC2 实例、AWS Lambda 函数、Kinesis 流、Amazon ECS 任务、Step Functions 状态机、Amazon SNS 主题、Amazon SQS 队列和内置目标。目标接收 JSON 格式的事件。
规则—规则匹配传入事件并将其路由到目标进行处理。
Amazon CloudWatch Logs
日志文件服务。应用程序的日志可上传到此,可以统一搜索,统计搜索日志表达式
功能
CloudWatch Logs Insights 分析日志数据。这个可以用于cross query多个service的log
如果日志是json
{ ($.user.email = "John.Stiles@example.com" || $.coordinates[0][1] = nonmatch) && $.actions[2] = nomatch }
功能
CloudWatch Logs Insights 分析日志数据。这个可以用于cross query多个service的log
CW的query支持一些aggregation操作如stats count(user_operation) by user
count_distinct 只返回估计值如果cardinality太高
CloudWatch Synthetic
Canary用于检测UI和API,replay traffic
AWS ElastiCache
分布式内存数据存储
使用场景
游戏排行榜
消息发送 (Redis Pub/Sub),Publisher和subcriber间的缓存
推荐数据(Redis 哈希)
功能
缓存节点故障的自动检测和恢复。
在支持复制的 Redis 集群中,将失败的主集群自动故障转移到只读副本的多可用区。
Redis (已启用集群模式)支持将数据划分到最多 90 个分片。
比较 Memcached 和 Redis
1. Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
2. Redis支持数据的备份,即master-slave模式的数据备份。
3. Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
抛开这些,可以深入到Redis内部构造去观察更加本质的区别,理解Redis的设计。
在Redis中,并不是所有的数据都一直存储在内存中的。这是和Memcached相比一个最大的区别。
Redis只会缓存所有的 key的信息,如果Redis发现内存的使用量超过了某一个阀值,将触发swap的操作
Ref
官方文档
使用场景
游戏排行榜
消息发送 (Redis Pub/Sub),Publisher和subcriber间的缓存
推荐数据(Redis 哈希)
功能
缓存节点故障的自动检测和恢复。
在支持复制的 Redis 集群中,将失败的主集群自动故障转移到只读副本的多可用区。
Redis (已启用集群模式)支持将数据划分到最多 90 个分片。
比较 Memcached 和 Redis
1. Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
2. Redis支持数据的备份,即master-slave模式的数据备份。
3. Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
抛开这些,可以深入到Redis内部构造去观察更加本质的区别,理解Redis的设计。
在Redis中,并不是所有的数据都一直存储在内存中的。这是和Memcached相比一个最大的区别。
Redis只会缓存所有的 key的信息,如果Redis发现内存的使用量超过了某一个阀值,将触发swap的操作
Ref
官方文档
AWS Elasticsearch
ES的AWS封装云服务,开源搜索和分析引擎
使用场景
适用于日志分析、实时应用程序监控、点击流分析等使用案例
使用场景
适用于日志分析、实时应用程序监控、点击流分析等使用案例
ES的意思是Full text search也就是一个text box根据词频用or来连接这些词来返回结果。
read-what-was-just-written performance. Search engines are better at really quick search with additional tricks like all kinds of normalization: lowercase, ä->a or ae, prefix matches, ngram matches (if indexed respectively)
另一个search是用户选择不同的field或者多个来search这种其实是query,不需要ES来实现。
最佳实践
Amazon S3(trigger->lambda)、Amazon Kinesis(data streams, firehose->lambda)和Amazon DynamoDB的CloudWatch, IoT集成,用于将流数据加载到 Amazon ES
DyanmoDB->stream->Lambda加载数据到ES
Kibana数据可视化
功能
Amazon ES 为您的 Elasticsearch 集群预置所有资源并启动集群。
它还自动检测和替换失败的 Elasticsearch 节点,减少与自管理基础设施相关的开销。
您只需调用一次 API 或在控制台中单击几下就可扩展集群
最多3 PB实例存储,常用Elasticsearch准则是不超过每个分片 50 GB
Amazon EBS存储卷
用于Kibana的Amazon Cognito 身份验证
自动快照用于备份和还原 Amazon ES 域
使用 Kibana 实现数据可视化
Domain
Elasticsearch 域名
EBS
带自动备份的云硬盘
快照
快照是群集的数据和状态的备份。状态包含集群设置、节点信息、索引设置和分片分配。
Logstash提供一种便捷的方式,通过 S3 插件使用批量 API 来上传数据到您的 Amazon ES 域
SQL支持
用Curator轮换数据
删除名称中包含的时间戳指示数据已超过 30 天的任何索引
底层API
见AWS Elasticsearch原理
Ref
官方文档
最佳实践
Amazon S3(trigger->lambda)、Amazon Kinesis(data streams, firehose->lambda)和Amazon DynamoDB的CloudWatch, IoT集成,用于将流数据加载到 Amazon ES
DyanmoDB->stream->Lambda加载数据到ES
Kibana数据可视化
功能
Amazon ES 为您的 Elasticsearch 集群预置所有资源并启动集群。
它还自动检测和替换失败的 Elasticsearch 节点,减少与自管理基础设施相关的开销。
您只需调用一次 API 或在控制台中单击几下就可扩展集群
最多3 PB实例存储,常用Elasticsearch准则是不超过每个分片 50 GB
Amazon EBS存储卷
用于Kibana的Amazon Cognito 身份验证
自动快照用于备份和还原 Amazon ES 域
使用 Kibana 实现数据可视化
Domain
Elasticsearch 域名
EBS
带自动备份的云硬盘
快照
快照是群集的数据和状态的备份。状态包含集群设置、节点信息、索引设置和分片分配。
Logstash提供一种便捷的方式,通过 S3 插件使用批量 API 来上传数据到您的 Amazon ES 域
SQL支持
用Curator轮换数据
删除名称中包含的时间戳指示数据已超过 30 天的任何索引
底层API
见AWS Elasticsearch原理
Ref
官方文档
Thursday, June 27, 2019
AWS SNS
通知云服务
Amazon Simple Notification Service (Amazon SNS) 是一项 Web 服务,用于协调和管理向订阅终端节点或客户端交付或发送消息的过程。订阅者(即 Web 服务器、电子邮件地址、Amazon SQS 队列、AWS Lambda 函数)在其订阅主题后通过受支持协议(即 Amazon SQS、HTTP/S、电子邮件、SMS、Lambda)之一使用或接收消息或通知。
接收通知没有API,一般以HTTP endpoint,邮件等方式接收。下面例子为HTTP endpoint (Java servlet)
多个内容发布者利用语音助手发布自己的事件,语音助手视频组只订阅视频内容提供者。Topic是内容发布者的内容id,Kafka均衡负载地将不同Topic发布给相应订阅者。Kafka还要把内容持久化到系统本地,然后保留一段时间后删除。而订阅者是否阅读某topic就由订阅者系统自己维护,Kafka不负责事件状态。
Ref
官网
Amazon Simple Notification Service (Amazon SNS) 是一项 Web 服务,用于协调和管理向订阅终端节点或客户端交付或发送消息的过程。订阅者(即 Web 服务器、电子邮件地址、Amazon SQS 队列、AWS Lambda 函数)在其订阅主题后通过受支持协议(即 Amazon SQS、HTTP/S、电子邮件、SMS、Lambda)之一使用或接收消息或通知。
使用场景
应用程序和系统警报时由预定义阈值触发的
通知推送电子邮件和文本消息
移动推送通知
通知推送电子邮件和文本消息
移动推送通知
架构
主题Topic
Amazon SNS 主题是一个逻辑访问点,可以充当通信通道。利用主题,您可以对多个终端节点(例如,AWS Lambda、Amazon SQS、HTTP/S 或电子邮件地址)进行分组。
Fanout
当 Amazon SNS 消息发送至主题且被复制和推送到多个 Amazon SQS 队列、HTTP 终端节点或电子邮件地址时,会出现“四散传播”场景。这允许进行并行异步处理。
观察着模式(我的观点)。
由使用场景可以知道,SNS的接受者种类有限。以邮件为例,信息广播后,就会立刻收到邮件,所以SNS主要功能是通知,并没有暂存信息的功能。所以很多时候与SQS连用,SQS提供存储空间。
111122223333为publisher的aws账号id,而Resource为subscriber账号的SNS topic的arn.
最佳实践
Baseline: Lambda1 -> SNS -> Lambda2 -> RDS (SNS可用于跨账号,SNS的拥有者为subscriber,因为需要setup filter policy,而SNS access policy只要指明publisher的AWS account id即可)111122223333为publisher的aws账号id,而Resource为subscriber账号的SNS topic的arn.
{
"Statement": [{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam:111122223333:root"
},
"Action": "sns:Publish",
"Resource": "arn:aws:sns:us-west-2:444455556666:MyTopic"
}]
}
"Statement": [{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam:111122223333:root"
},
"Action": "sns:Publish",
"Resource": "arn:aws:sns:us-west-2:444455556666:MyTopic"
}]
}
Filter policy用SNSMessageAttributes来实现,实质上是一个Map。Filter时候用
{
"Type": ["Feature"]
}
SNS->Lambda
SQS->SNS->SQS client
Amazon SNS 让应用程序通过“推送”机制将紧急消息发送给多个订阅者,并且无需定期检查
或“轮询”更新。
Amazon SQS 是分布式应用程序用于通过轮询模式来交换消息的消息队列服务,可用于分离
各个组成
部分的发送和接收而不要求所有组成部分都同时可用。
Amazon SNS 当前与 Amazon SQS FIFO 队列不兼容。
SNS->HTTP(S)
SNS->push on phone, 适用于 iOS 和 Mac OS X 的 Apple Push Notification Service (APNS)
SNS->SMS on phone
SNS->Lambda
SQS->SNS->SQS client
Amazon SNS 让应用程序通过“推送”机制将紧急消息发送给多个订阅者,并且无需定期检查
或“轮询”更新。
Amazon SQS 是分布式应用程序用于通过轮询模式来交换消息的消息队列服务,可用于分离
各个组成
部分的发送和接收而不要求所有组成部分都同时可用。
Amazon SNS 当前与 Amazon SQS FIFO 队列不兼容。
SNS->HTTP(S)
SNS->push on phone, 适用于 iOS 和 Mac OS X 的 Apple Push Notification Service (APNS)
SNS->SMS on phone
底层API
final SubscribeRequest subscribeRequest = new SubscribeRequest(topicArn, "email",
"name@example.com");
"name@example.com");
snsClient.subscribe(subscribeRequest);
final String msg = "If you receive this message, publishing a message to an Amazon SNS topic works.";
final PublishRequest publishRequest = new PublishRequest(topicArn, msg);
final PublishResult publishResponse = snsClient.publish(publishRequest);
接收通知没有API,一般以HTTP endpoint,邮件等方式接收。下面例子为HTTP endpoint (Java servlet)
Scanner scan = new Scanner(request.getInputStream());
StringBuilder builder = new StringBuilder();
while (scan.hasNextLine()) {
builder.append(scan.nextLine());
Message msg = readMessageFromJson(builder.toString());
功能
消息筛选
主题订阅者仅接收一部分消息,订阅者必须定义筛选策略。当您将一条消息发布到某个主题时,Amazon SNS 会比较该消息属性与该主题的每个订阅的筛选策略中的属性。如果任何属性匹配,Amazon SNS 会将消息发送给订阅者。否则,Amazon SNS 会跳过订阅者而不向其发送消息。如果某个订阅没有筛选策略,则该订阅将接收发布到其主题的每条消息。
向不同账户中的 Amazon SQS 队列发送 Amazon SNS 消息。
通过将 HTTP/S 终端节点作为订阅者
您可以使用 Amazon SNS 向一个或多个 HTTP 或 HTTPS 终端节点发送通知消息。为终端节点订阅主题时,您可以向主题发布通知,Amazon SNS 将发送 HTTP POST 请求,向已订阅终端节点传递通知内容。
主题订阅者仅接收一部分消息,订阅者必须定义筛选策略。当您将一条消息发布到某个主题时,Amazon SNS 会比较该消息属性与该主题的每个订阅的筛选策略中的属性。如果任何属性匹配,Amazon SNS 会将消息发送给订阅者。否则,Amazon SNS 会跳过订阅者而不向其发送消息。如果某个订阅没有筛选策略,则该订阅将接收发布到其主题的每条消息。
向不同账户中的 Amazon SQS 队列发送 Amazon SNS 消息。
通过将 HTTP/S 终端节点作为订阅者
您可以使用 Amazon SNS 向一个或多个 HTTP 或 HTTPS 终端节点发送通知消息。为终端节点订阅主题时,您可以向主题发布通知,Amazon SNS 将发送 HTTP POST 请求,向已订阅终端节点传递通知内容。
与Kafka比较
Amazon自主开发的一套发布者-订阅者系统,类似于Apache Kafka。用于股票实时统计,用户消息通知(LinkedIn),游戏中交易通知或预警。多个内容发布者利用语音助手发布自己的事件,语音助手视频组只订阅视频内容提供者。Topic是内容发布者的内容id,Kafka均衡负载地将不同Topic发布给相应订阅者。Kafka还要把内容持久化到系统本地,然后保留一段时间后删除。而订阅者是否阅读某topic就由订阅者系统自己维护,Kafka不负责事件状态。
Ref
官网
Wednesday, April 17, 2019
Tuesday, April 2, 2019
ES2018简介
中括号
const numbers = [1, 2, 3, 4, 5]
[first, second, ...others] = numbers
小括号
const numbers = [1, 2, 3, 4, 5]
const sum = (a, b, c, d, e) => a + b + c + d + e
const sumOfNumbers = sum(...numbers)
大括号
const { first, second, ...others } = { first: 1, second: 2, third: 3, fourth: 4, fifth: 5 }
first // 1
second // 2
others // { third: 3, fourth: 4, fifth: 5 }
const items = { first, second, ...others }
items //{ first: 1, second: 2, third: 3, fourth: 4, fifth: 5 }
some:
return the first one-> true/false without going through all elements
[2, 5, 8, 1, 4].some(isBiggerThan10);
map:
let r = res.map(item => {
return {
title: item.name,
sex: item.sex === 1? '男':item.sex === 0?'女':'保密',
age: item.age,
avatar: item.img
}
})
filter:
var marvelHeroes = heroes.filter(function(hero) {
return hero.franchise == “Marvel”;
});
ES2018
const numbers = [1, 2, 3, 4, 5]
[first, second, ...others] = numbers
小括号
const numbers = [1, 2, 3, 4, 5]
const sum = (a, b, c, d, e) => a + b + c + d + e
const sumOfNumbers = sum(...numbers)
大括号
const { first, second, ...others } = { first: 1, second: 2, third: 3, fourth: 4, fifth: 5 }
first // 1
second // 2
others // { third: 3, fourth: 4, fifth: 5 }
const items = { first, second, ...others }
items //{ first: 1, second: 2, third: 3, fourth: 4, fifth: 5 }
some:
return the first one-> true/false without going through all elements
[2, 5, 8, 1, 4].some(isBiggerThan10);
map:
let r = res.map(item => {
return {
title: item.name,
sex: item.sex === 1? '男':item.sex === 0?'女':'保密',
age: item.age,
avatar: item.img
}
})
filter:
var marvelHeroes = heroes.filter(function(hero) {
return hero.franchise == “Marvel”;
});
ES2018
Wednesday, March 27, 2019
Saturday, March 23, 2019
xposed
http://www.oneplusbbs.com/thread-4037966-1.html
https://repo.xposed.info/module-overview
https://kuaibao.qq.com/s/20180417G1VSM600?refer=spider
https://www.jianshu.com/p/393f5e51716e
https://repo.xposed.info/module-overview
https://kuaibao.qq.com/s/20180417G1VSM600?refer=spider
https://www.jianshu.com/p/393f5e51716e
Thursday, March 21, 2019
NodeJS的debounce和throttle区别
axios是一个NodeJS的库,它含有两个函数来避免发过多request到后端,从而提高相应。
debounce防抖动:把触发非常频繁的事件(比如按键)合并成一次执行。若此时间段内,只有一个事件,它会在时钟的末尾执行。例子:autocomplete,resize等需要等待用户按键结束的用例。
throttle节流:保证每 X 毫秒恒定的执行次数。例子:无限滚动,没有事件或者事件带连续性的用例。
区别就是,防抖动是时间做阈值,而throttle就是用数量做阈值。例如automplete用防抖动实现,如果用户输入速度快于阈值,就不会发request到后端,只有当某次输入超过阈值,也就是这段时间内只有一个输入,才会发到后端。也可以看出防抖动属于延迟执行,也就是等待时间阈值后才实际执行。而节流是立即执行,但该时间段内其他的不再执行。还是用autocomplete的例子,若用节流实现的话,即使用户输入快于时间阈值,request还是会发,只发一个。
cancelToken: debounce还和cancelToken一起用,表示若发到后端的request已经发出,而用户现在输入,前端即使受到response也不再处理。若无此,可能输入新字母后还会出现前一次结果。甚至用户跳转到新页面了,网站当收到response后悔跳转到旧页面,用户会感到非常奇怪。
解释
官网定义
区别
debounce防抖动:把触发非常频繁的事件(比如按键)合并成一次执行。若此时间段内,只有一个事件,它会在时钟的末尾执行。例子:autocomplete,resize等需要等待用户按键结束的用例。
throttle节流:保证每 X 毫秒恒定的执行次数。例子:无限滚动,没有事件或者事件带连续性的用例。
区别就是,防抖动是时间做阈值,而throttle就是用数量做阈值。例如automplete用防抖动实现,如果用户输入速度快于阈值,就不会发request到后端,只有当某次输入超过阈值,也就是这段时间内只有一个输入,才会发到后端。也可以看出防抖动属于延迟执行,也就是等待时间阈值后才实际执行。而节流是立即执行,但该时间段内其他的不再执行。还是用autocomplete的例子,若用节流实现的话,即使用户输入快于时间阈值,request还是会发,只发一个。
cancelToken: debounce还和cancelToken一起用,表示若发到后端的request已经发出,而用户现在输入,前端即使受到response也不再处理。若无此,可能输入新字母后还会出现前一次结果。甚至用户跳转到新页面了,网站当收到response后悔跳转到旧页面,用户会感到非常奇怪。
解释
官网定义
区别
Sunday, March 10, 2019
Guava Cache简介
Guava Cache是一个全内存的本地缓存实现,它提供了线程安全的实现机制。整体上来说Guava cache 是本地缓存的不二之选,简单易用,性能好。相对于distributed cache而言
http://www.cnblogs.com/peida/p/Guava_Cache.html
https://www.jianshu.com/p/afe7b2dccee0
http://www.cnblogs.com/peida/p/Guava_Cache.html
https://www.jianshu.com/p/afe7b2dccee0
Tuesday, March 5, 2019
流式分页 Pagination
传统分页和流式分页
无页码
无上/下页按钮
不可跳转至指定页面
pc端和移动端均有使用
后端实现:
用offset和limit来实现(mysql)
当前页数据(及其之前)若有增加,由于计算问题total/limit*offset,数据整体下移(变多),指针相对上移,会出现数据重复。
2. 后端方案,用cursor记录最后一个ID。这叫游标式分页。DynamoDB采用这个方案。pagination token带有过期时间戳。
3. 前端方案,一次性发所有Id,缓存到前端。
4. 前端方案,客户端保留已浏览数据,手动去重。不能避免数据缺失。
1. 单一排序:这个顺序是固定的,而且可以快速定位到这个ID。
2. 追加式:只能添加和删除一行,不能更新某些域。更新它们若影响排序的话,就涉及数据快照概念。若第一页分页请求产生时(方案一)生成时间戳,这个时间戳对应整套数据的快照,若某些域在这个时间戳之后更新(可以按行来添加lastUpdateTime),按照设计,应该显示旧值。这要求每个域所有更新都要有历史记录。此解决方案有利有弊:可以避免数据重复出现,但是新数据会不显示。
流式分页应用场景:
通过滚动/上拉/点击等方式加载新一页无页码
无上/下页按钮
不可跳转至指定页面
pc端和移动端均有使用
实现:
前端实现:后端返回全部结果,前端做分页后端实现:
用offset和limit来实现(mysql)
优化:
当前页数据(及其之前)若有删除,由于计算问题total/limit*offset,数据整体上移(变少),指针相对下移,会出现数据缺失。当前页数据(及其之前)若有增加,由于计算问题total/limit*offset,数据整体下移(变多),指针相对上移,会出现数据重复。
方案:
1. 后端方案,缓存数据2. 后端方案,用cursor记录最后一个ID。这叫游标式分页。DynamoDB采用这个方案。pagination token带有过期时间戳。
3. 前端方案,一次性发所有Id,缓存到前端。
4. 前端方案,客户端保留已浏览数据,手动去重。不能避免数据缺失。
游标式分页
这个方案避免了数据缺失和重复,但有适用范围。它仅能用于追加式的单一排序。这要求1. 单一排序:这个顺序是固定的,而且可以快速定位到这个ID。
2. 追加式:只能添加和删除一行,不能更新某些域。更新它们若影响排序的话,就涉及数据快照概念。若第一页分页请求产生时(方案一)生成时间戳,这个时间戳对应整套数据的快照,若某些域在这个时间戳之后更新(可以按行来添加lastUpdateTime),按照设计,应该显示旧值。这要求每个域所有更新都要有历史记录。此解决方案有利有弊:可以避免数据重复出现,但是新数据会不显示。
* 快照模式:用lastUpdatedTimestamp
* 若要实现scroll down时候,新加入的entries也显示,这不属于快照模式,可以用timestamp的UUID, uuid > last-entry-uuid就可以,缺点是符号条件的entry只能按插入时间顺序排序而不能按其他条件排序
// Query the first page.
let result = await MongoPaging.find(db.collection('myobjects'), {
limit: 2
});
console.log(result);
// Query next page.
result = MongoPaging.find(db.collection('myobjects'), {
limit: 2,
next: result.next // This queries the next page
});
console.log(result);
}
Response:
page 1 { results:
[ { _id: 580fd16aca2a6b271562d8bb, counter: 4 },
{ _id: 580fd16aca2a6b271562d8ba, counter: 3 } ],
next: 'eyIkb2lkIjoiNTgwZmQxNmFjYTJhNmIyNzE1NjJkOGJhIn0',
hasNext: true }
page 2 { results:
[ { _id: 580fd16aca2a6b271562d8b9, counter: 2 },
{ _id: 580fd16aca2a6b271562d8b8, counter: 1 } ],
previous: 'eyIkb2lkIjoiNTgwZmQxNmFjYTJhNmIyNzE1NjJkOGI5In0',
next: 'eyIkb2lkIjoiNTgwZmQxNmFjYTJhNmIyNzE1NjJkOGI4In0',
hasNext: false }
Request中的limit的返回结果的大小,next上改页结果的最后一项的id,也就是下一页结果需要从这个项目后开始查找。
Response中的token是 {_id: 123} 的base64 encode. 比如page 1的next就是第二个(最后一个)id的encode。hasNext的设计可以让客户更清晰地知道是否有下一页,当然也可以用next=''来替代。
在有些设计中,token加入timestamp, {_id: 123, timestamp: 2019-06-21 12:23:11},设一个SLA为24小时,也就是下一个翻页请求在SLA内完成,这样可以减少不必要的请求。
Ref
[1] https://aotu.io/notes/2017/06/27/infinite-scrolling/index.html
[2] MongoDB实现
[3] 游标式分页的优势
MongoDB的游标式实现
Request:// Query the first page.
let result = await MongoPaging.find(db.collection('myobjects'), {
limit: 2
});
console.log(result);
// Query next page.
result = MongoPaging.find(db.collection('myobjects'), {
limit: 2,
next: result.next // This queries the next page
});
console.log(result);
}
Response:
page 1 { results:
[ { _id: 580fd16aca2a6b271562d8bb, counter: 4 },
{ _id: 580fd16aca2a6b271562d8ba, counter: 3 } ],
next: 'eyIkb2lkIjoiNTgwZmQxNmFjYTJhNmIyNzE1NjJkOGJhIn0',
hasNext: true }
page 2 { results:
[ { _id: 580fd16aca2a6b271562d8b9, counter: 2 },
{ _id: 580fd16aca2a6b271562d8b8, counter: 1 } ],
previous: 'eyIkb2lkIjoiNTgwZmQxNmFjYTJhNmIyNzE1NjJkOGI5In0',
next: 'eyIkb2lkIjoiNTgwZmQxNmFjYTJhNmIyNzE1NjJkOGI4In0',
hasNext: false }
Request中的limit的返回结果的大小,next上改页结果的最后一项的id,也就是下一页结果需要从这个项目后开始查找。
Response中的token是 {_id: 123} 的base64 encode. 比如page 1的next就是第二个(最后一个)id的encode。hasNext的设计可以让客户更清晰地知道是否有下一页,当然也可以用next=''来替代。
在有些设计中,token加入timestamp, {_id: 123, timestamp: 2019-06-21 12:23:11},设一个SLA为24小时,也就是下一个翻页请求在SLA内完成,这样可以减少不必要的请求。
Ref
[1] https://aotu.io/notes/2017/06/27/infinite-scrolling/index.html
[2] MongoDB实现
[3] 游标式分页的优势
Tuesday, February 12, 2019
AWS RDS
Sunday, February 10, 2019
React 简介
React引入是解决网站由于数据更新而重新刷新页面的效率问题。它比较数据变化引起的页面变化(page diff)而只刷新相应的前端,从而大大提高效率。
<script type="text/jsx">
// ** Our code goes here! **
</script>
HTML 语言直接写在 JavaScript 语言之中,不加任何引号。遇到 HTML 标签(以 < 开头),就用 HTML 规则解析;遇到代码块(以 { 开头),就用 JavaScript 规则解析。
var arr = [
<h1>Hello world!</h1>,
<h2>React is awesome</h2>,
];
React.render(
<div>{arr}</div>,
document.getElementById('example')
);
var LikeButton = React.createClass({
getInitialState: function() {
return {liked: false};
},
handleClick: function(event) {
this.setState({liked: !this.state.liked});
},
render: function() {
var text = this.state.liked ? 'like' : 'haven\'t liked';
return (
<p onClick={this.handleClick}>
You {text} this. Click to toggle.
</p>
);
}
});
React.render(
<LikeButton />,
document.getElementById('example')
);
这个LikeButton是一个接受空参数的组件。若需要输入参数到组件,请见组件间通信。
某个组件的状态,需要共享
某个状态需要在任何地方都可以拿到
一个组件需要改变全局状态
各组件之间的通信用state(Redux)作为媒介。这是在传统上新加的抽象层,也就是HTML和JS之间加入Redux层用状态传递。Action是变化obj,Reducer是biz逻辑处理函数,输入是previous state, Action,输出是new state。
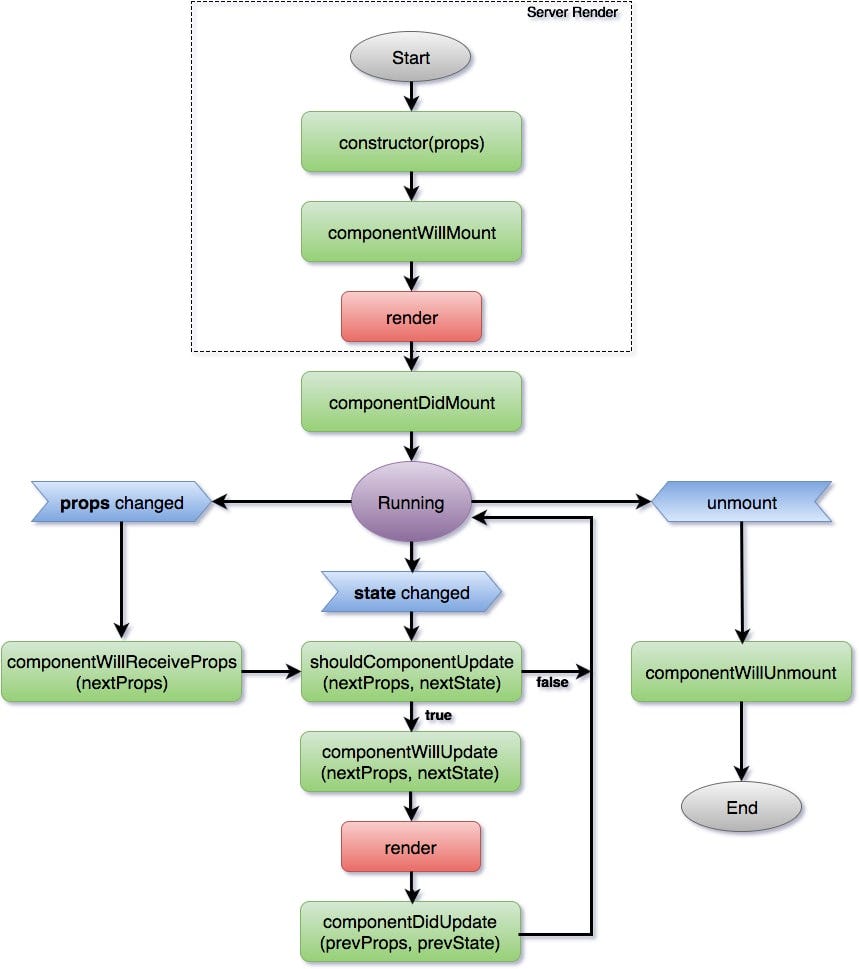
Mounting: component加到DOM.
Updates: component接收props或state改动,component重新render.
Unmounting: component从DOM中删除
经常需要更新的组件就放在updates,static的部分就在mounting。
componnetWillReceiveProps(nextProps) {
this.setState({selectedOptions: nextProps.selectedOptions});
}
可以将props的改变放入到state里面从而re-render
render() {
const data = [{
name: 'Tanner Linsley',
age: 26,
friend: {
name: 'Jason Maurer',
age: 23,
}
},{
...
}]
const columns = [{
Header: 'Name',
accessor: 'name' // String-based value accessors!
}, {
Header: 'Age',
accessor: 'age',
Cell: props => <span className='number'>{props.value}</span> // Custom cell components!
}]
return <ReactTable
data={data}
columns={columns}
/>
}
Ref
ReactJS简介
React简书
Redux
Life cycle
组件通信
React table
React filtered multiselect
React data range picker
JSX
JSX是React发明的类型,<script type="text/jsx">
// ** Our code goes here! **
</script>
HTML 语言直接写在 JavaScript 语言之中,不加任何引号。遇到 HTML 标签(以 < 开头),就用 HTML 规则解析;遇到代码块(以 { 开头),就用 JavaScript 规则解析。
var arr = [
<h1>Hello world!</h1>,
<h2>React is awesome</h2>,
];
React.render(
<div>{arr}</div>,
document.getElementById('example')
);
React.render()
React.render 是 React 的最基本方法,用于将模板转为 HTML 语言,并插入指定的 DOM 节点(第二个参数)。this.props 和 this.state
this.props 对象的属性与组件的属性一一对应。由于 this.props 和 this.state 都用于描述组件的特性,可能会产生混淆。一个简单的区分方法是,this.props 表示那些一旦定义如href,就不再改变的特性,而 this.state 是会随着用户互动而产生变化的特性(用户输入)。var LikeButton = React.createClass({
getInitialState: function() {
return {liked: false};
},
handleClick: function(event) {
this.setState({liked: !this.state.liked});
},
render: function() {
var text = this.state.liked ? 'like' : 'haven\'t liked';
return (
<p onClick={this.handleClick}>
You {text} this. Click to toggle.
</p>
);
}
});
React.render(
<LikeButton />,
document.getElementById('example')
);
这个LikeButton是一个接受空参数的组件。若需要输入参数到组件,请见组件间通信。
Redux
Redux是网站的cache层,用来保存组件状态。使用场景:某个组件的状态,需要共享
某个状态需要在任何地方都可以拿到
一个组件需要改变全局状态
各组件之间的通信用state(Redux)作为媒介。这是在传统上新加的抽象层,也就是HTML和JS之间加入Redux层用状态传递。Action是变化obj,Reducer是biz逻辑处理函数,输入是previous state, Action,输出是new state。
Lifecycle
Mounting: component加到DOM.
Updates: component接收props或state改动,component重新render.
Unmounting: component从DOM中删除
经常需要更新的组件就放在updates,static的部分就在mounting。
componnetWillReceiveProps(nextProps) {
this.setState({selectedOptions: nextProps.selectedOptions});
}
可以将props的改变放入到state里面从而re-render
React Table
import ReactTable from 'react-table'render() {
const data = [{
name: 'Tanner Linsley',
age: 26,
friend: {
name: 'Jason Maurer',
age: 23,
}
},{
...
}]
const columns = [{
Header: 'Name',
accessor: 'name' // String-based value accessors!
}, {
Header: 'Age',
accessor: 'age',
Cell: props => <span className='number'>{props.value}</span> // Custom cell components!
}]
return <ReactTable
data={data}
columns={columns}
/>
}
Component
组件概念:就是为了可以复用,提供定制化参数如css classname, 输入数据。
如filtered-multiselect提供onchange函数定制,options列表等。可以把它封装成一个自定义component提供给自己网站的其他网页使用。类似的组件还有data range picker网上很多开源的组件并不需要自己造。
<FilteredMultiSelect
onChange={this.handleSelectionChange}
options={CULTURE_SHIPS}
selectedOptions={selectedShips}
textProp="name"
valueProp="id"
/>
组件间的通信
父向子,就是调用子组件时就会提供参数到其构造函数
父
return <ReactTable
data={data}
columns={columns}
/>
子
ReactTable.propTypes = {
data: PropTypes.array.isRequired,
columns: PropTypes.array.isRequired,
}
怎么用
console.log(this.props.data);
子向父,通过绑定父和子函数实现,如例子中绑定子组件的onSave和父组件的handleSave。通过此句来实现。当子组件的状态变化(用户输入),就会触发父组件写入其另一个Li的子组件中。
<InputAndButton onSave={this.handleSave.bind(this)}/>
父
<InputAndButton
title="abc"
onSave={this.handleSave.bind(this)}/>
return <ReactTable
data={data}
columns={columns}
/>
子
ReactTable.propTypes = {
data: PropTypes.array.isRequired,
columns: PropTypes.array.isRequired,
}
怎么用
console.log(this.props.data);
子向父,通过绑定父和子函数实现,如例子中绑定子组件的onSave和父组件的handleSave。通过此句来实现。当子组件的状态变化(用户输入),就会触发父组件写入其另一个Li的子组件中。
<InputAndButton onSave={this.handleSave.bind(this)}/>
父
handleSave(text){
if(text.length !== 0){
this.state.items.push({key: new Date().getTime(), text});
this.setState({
items: this.state.items,
})
}
};
<InputAndButton
title="abc"
onSave={this.handleSave.bind(this)}/>
子
this.props.onSave(this.state.inputValue.trim());
console.log(this.props.title); //输入参数值
InputAndButton.defaultProps = {
title: 'Button';
};
InputAndButton.propTypes = {
title: PropTypes.string,
title: PropTypes.string.isRequired,
};
propTypes是这个表示这个组件构造函数的输入参数,defaultProps表示默认值。注意如果父子孙三重关系,可以将子的props传入孙中,不要在子中奖props赋值到state然后将state传到孙,这样state会出现不sync。
in-style css
style={{marginLeft: 40}}
console.log(this.props.title); //输入参数值
InputAndButton.defaultProps = {
title: 'Button';
};
InputAndButton.propTypes = {
title: PropTypes.string,
title: PropTypes.string.isRequired,
};
propTypes是这个表示这个组件构造函数的输入参数,defaultProps表示默认值。注意如果父子孙三重关系,可以将子的props传入孙中,不要在子中奖props赋值到state然后将state传到孙,这样state会出现不sync。
in-style css
style={{marginLeft: 40}}
Ref
ReactJS简介
React简书
Redux
Life cycle
组件通信
React table
React filtered multiselect
React data range picker
Mutation Test 简介
Unit test的Line coverage很容易达到100%,但是并不能衡量测试的质量。Mutation test的引入就是解决这个问题。它通过修改程序然后跑现有的tests,如果tests没有fail的话,表示mutation coverage不好,所以mutation test是反着(每次否定一个语句)来跑测试的。Java的mutation test的框架主要是Pitest。
概念
Mutant: 每一个代码改动Mutation: 修改了的程序
Killed: 一个mutation不能通过unit test,这叫此mutation被杀死了,这是我们想见到的。
Survived: 一个mutation还能通过unit test,这叫此mutation存活了。
下面这个程序是判断一个字符串是否Palindrome。用首尾字符比较然后向中心字符串递归。
public boolean isPalindrome(String inputString) {
if (inputString.length() == 0) {
return true;
} else {
char firstChar = inputString.charAt(0);
char lastChar = inputString.charAt(inputString.length() - 1);
String mid = inputString.substring(1, inputString.length() - 1);
return (firstChar == lastChar)
&& isPalindrome(mid);
}
}
Unit test如下,它的code coverage是100%,但是它mutation coverage只有6/8。它两个地方没有被NEGATE_CONDITIONALS_MUTATOR杀死。
@Test
public void whenPalindrom_thenAccept() {
Palindrome palindromeTester = new Palindrome();
assertTrue(palindromeTester.isPalindrome("noon"));
}
第一处,若程序修改成 if (inputString.length() != 0),单元测试仍可以通过,因为任何非空字符串包括noon直接返回true了。这表示我们缺少failure test,加入下面这个:
@Test
public void whenNotPalindrom_thanReject() {
Palindrome palindromeTester = new Palindrome();
assertFalse(palindromeTester.isPalindrome("box"));
}
加入了第二个测试后。第二处,也就是程序改成&& !isPalindrome(mid),仍然survived,比较tricky。oo -->false, noon->true & !f(oo)= true, 双重否定后仍然是成立。所以加入只有有一组首尾相等的测试如neon即可。
@Test
public void whenNearPalindrom_thanReject() {
Palindrome palindromeTester = new Palindrome();
assertFalse(palindromeTester.isPalindrome("neon"));
}
Mutator
包括7个默认的MutatorConditionals Boundary Mutator。 如<= to <
Increments Mutator。如i++ to i--
Invert Negatives Mutator。如return i to return -i
Math Mutator。如b+c to b-c
Negate Conditionals Mutator。如== to !=,这个是最普遍的会survive的。
Return Values Mutator。如return new Object() to return null
Void Method Calls Mutator。如someMethod() to (method removed)。这个也普遍。
其他Mutator
Constructor Call Mutator。如Object o = new Object to Object o = null
Empty returns Mutator。如return "abc" to return ""
Config
--threads表示用多少个线程跑--mutators用什么mutator
--coverageThreshold测试覆盖率
--targetClasses只测试某个包下面的class
--targetTests只测试某个TestClass
--timeoutConst某个测试的时间上限。这个影响全部测试的时间,因为有些mutation可能会导致死循环,当然也算是failed的。
Incremental Analysis
可以配置来减少每次跑测试的时间。因为通过比较代码改动和上次测试结果,新一轮测试只会incremental跑。Ref
http://pitest.org/quickstart/mutators/https://www.baeldung.com/java-mutation-testing-with-pitest
https://www.testwo.com/article/869
Friday, January 11, 2019
Tuesday, January 8, 2019
Monday, January 7, 2019
Wednesday, January 2, 2019
MyBatis简介
SqlSessionFactory是单例模式
从SqlSessionFactory中获取SqlSession
SqlSession调用Mapper
public interface BlogMapper {
@Select("SELECT * FROM blog WHERE id = #{id}")
Blog selectBlog(int id);
}
BlogMapper mapper = session.getMapper(BlogMapper.class);
Blog blog = mapper.selectBlog(101);
将上述SQL语句写到XML中
resultType直接映射到自定义类,resultMap是哈希表,手动映射
<select id="selectUsers" resultType="User">
select id, username, password
from users
where id = #{id}
</select>
<select id="selectUsers" resultMap="userResultMap">
select user_id, user_name, hashed_password
from some_table
where id = #{id}
</select>
<resultMap id="userResultMap" type="User">
<id property="id" column="user_id" />
<result property="username" column="user_name"/>
<result property="password" column="hashed_password"/>
</resultMap>
动态SQL的if, choose, when, otherwise, trim, where, set, foreach, bind语句
java -jar mybatis-generator-core-1.3.2.jar -configfile generator.xml -overwrite
BlogMapper m
自动生成文件有4个包括:
Student.java: table对应的java object
StudentMapper.xml用于mybatis生成java的指导文件
StudentMapper.java: 对表格增删减除的操作
StudentExample.java: 用于产生对每个column的大于等于小于条件判断
updateByExample, updateByEampleSelective区别
Example的意思是where条件,所以updateByExample(User, UserExample)是按where条件更新Object的全部字段,若为空,直接更新。
updateByEampleSelective(User, UserExample)是按where条件更新Object的某些字段(不为null),所以null的话,myBatis就不会更新。所以如果选用Selective的API,就不能将该字段更新为null,因为null是一个保留字来决定是否更新该字段。
updateByPrimaryKey(User)按主键更新,主键设在User中,这里就不用指定where条件。updateByExampleSelective按主键更新非null字段。
MyBatis简介
MyBatis Generator
updateByExample介绍
从SqlSessionFactory中获取SqlSession
SqlSession调用Mapper
public interface BlogMapper {
@Select("SELECT * FROM blog WHERE id = #{id}")
Blog selectBlog(int id);
}
BlogMapper mapper = session.getMapper(BlogMapper.class);
Blog blog = mapper.selectBlog(101);
resultType直接映射到自定义类,resultMap是哈希表,手动映射
<select id="selectUsers" resultType="User">
select id, username, password
from users
where id = #{id}
</select>
<select id="selectUsers" resultMap="userResultMap">
select user_id, user_name, hashed_password
from some_table
where id = #{id}
</select>
<resultMap id="userResultMap" type="User">
<id property="id" column="user_id" />
<result property="username" column="user_name"/>
<result property="password" column="hashed_password"/>
</resultMap>
动态SQL的if, choose, when, otherwise, trim, where, set, foreach, bind语句
java -jar mybatis-generator-core-1.3.2.jar -configfile generator.xml -overwrite
BlogMapper m
自动生成文件有4个包括:
Student.java: table对应的java object
StudentMapper.xml用于mybatis生成java的指导文件
StudentMapper.java: 对表格增删减除的操作
StudentExample.java: 用于产生对每个column的大于等于小于条件判断
updateByExample, updateByEampleSelective区别
Example的意思是where条件,所以updateByExample(User, UserExample)是按where条件更新Object的全部字段,若为空,直接更新。
updateByEampleSelective(User, UserExample)是按where条件更新Object的某些字段(不为null),所以null的话,myBatis就不会更新。所以如果选用Selective的API,就不能将该字段更新为null,因为null是一个保留字来决定是否更新该字段。
updateByPrimaryKey(User)按主键更新,主键设在User中,这里就不用指定where条件。updateByExampleSelective按主键更新非null字段。
MyBatis简介
MyBatis Generator
updateByExample介绍
Subscribe to:
Comments (Atom)